| 2020.11.23. | 초안작성 |
|---|
이 글은 1대 서버요정 minostauros - github profile이 만들어낸 연구실의 GPU Cluster를 유지보수하고 있는 2대 서버요정(a.k.a me)이 정리를 위해 쓰는 글이다.
고작 연구실 서버 관리가 무에 대수라고 블로그 글까지 쓰나...
위와 같은 생각이 드는 사람을 위해 우선 문제를 정의하고 가려고 한다.
2018년 인공지능 그랜드챌린지 우승과 다년간의 우수한 탑티어 컨퍼런스 논문 실적으로 이런저런 과제를 많이 받은 연구실은 서버의 수가 기하급수적으로 늘어나게 된다. 그와 함께 이를 관리해야할 필요성도 생기게 된다.
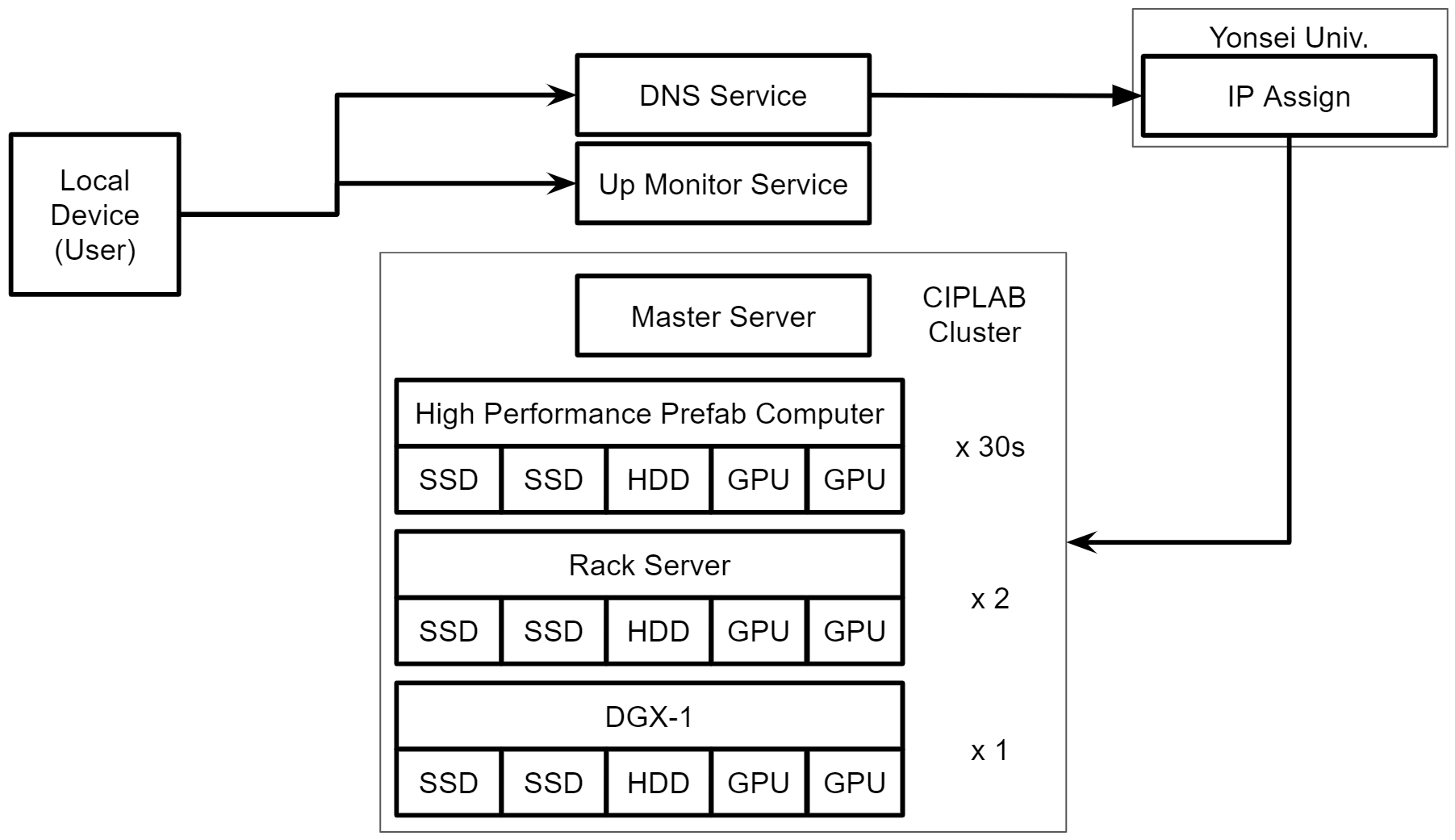
2020년 11월 23일 기준으로 조립 컴퓨터 36대, 랙서버 2대, DGX-1 1대를 보유하고 있다. 대부분의 조립컴, 랙서버에는 3~4개의 GPU가 들어가서 약 120개의 GPU를 보유하고 있는 셈이다.
여기서 이제 문제에 봉착하게 된다. 30명이 넘는 연구실 구성원이 120개의 GPU를 공간,시간 효율적으로 사용하기 위해서는 어떤 시스템과 정책을 갖춰야할까?
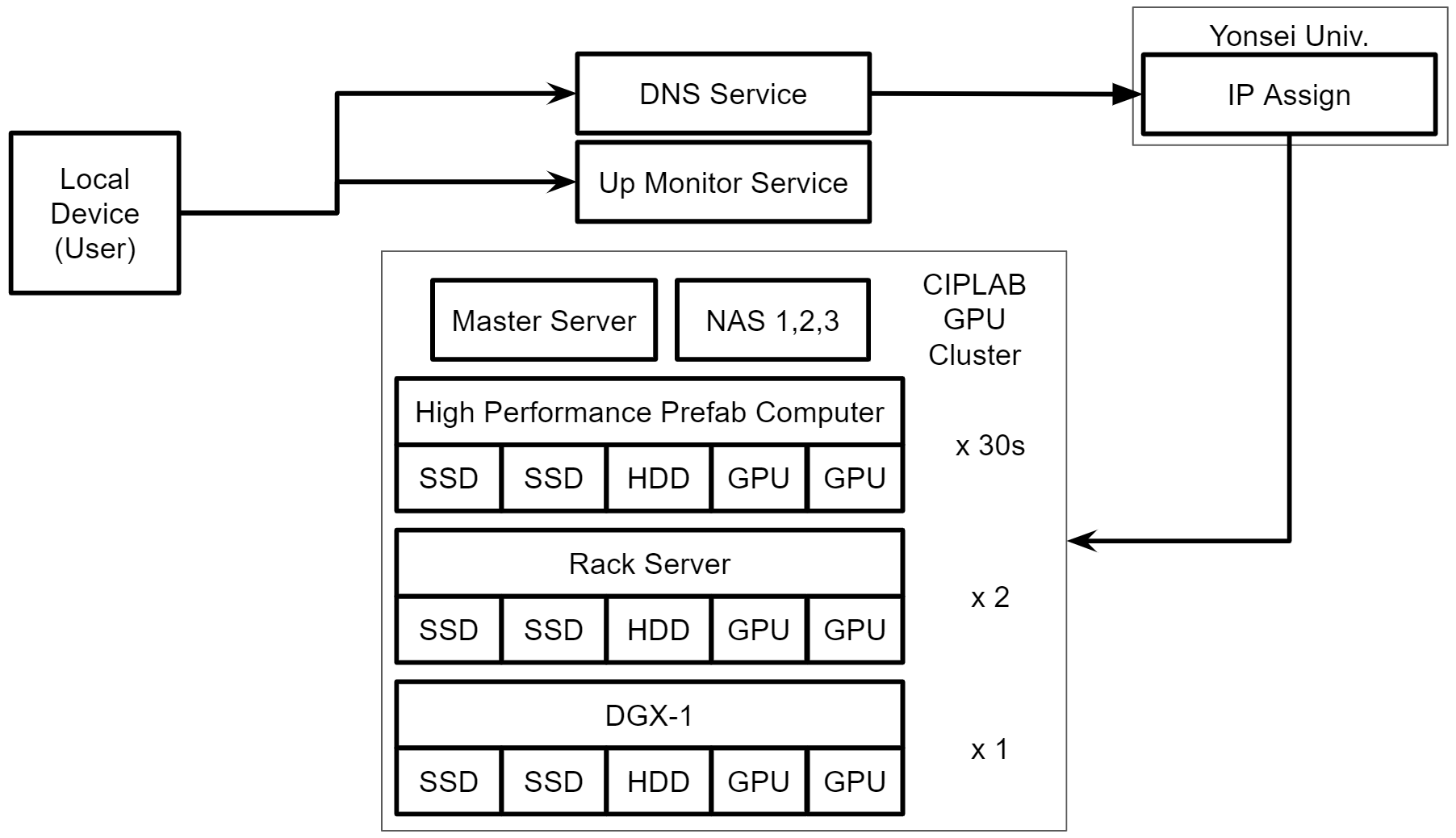
CIPLAB GPU Cluster Overview
sol1은 가장 자동화되어 있지 않은 방식이고 sol2는 가장 자동화되어있다. 그로인해 아래와 같은 장단점이 발생하게 된다.
| sol1 | sol2 | |
|---|---|---|
| 장점 | 서버 관리의 불필요 | 모든 자원을 효율적으로 자원들을 활용 |
| 단점 | 효율적인 사용이 불가능(e.g. 특정 개인이나 팀 유휴) | 클라우드 컴퓨팅 서비스 유지보수 필요 |